Пишем свой парсер Яндекс Wordstat, используя API Директа!

Всем привет! В предыдущей статье по Яндекс Wordstat я упомянул о возможности облегчить себе жизнь при подборе ключей с помощью API Директа. Как и обещал, я поделюсь своим скриптом на Python, который автоматизирует процесс сбора ключевых фраз. Разберем, как работает парсер Яндекс Wordstat на конкретном примере и, попутно, научимся получать доступ к API Директа и немножко кодить на Python).
Содержание статьи
API Директа
Думаю, долго распинаться на тему того, что такое Яндекс Директ необходимости нет) Здесь все более или менее в курсе, что такое реклама в интернете, какие виды рекламы бывают и насколько солидный кусок пирога в этом плане у Яндекса.
Кстати, напомню, что кроме контекстной рекламы существует условно-бесплатный трафик из соцсетей. Обязательно ознакомьтесь с моей статьей на эту тему!
Яндекс дружит с разработчиками и, предоставляет в свободное пользование доступ ко многим сервисам через программный интерфейс (API). За вопросы, которые касаются создания и ведения рекламных кампаний, отвечает сервис Яндекс Директ. И у него тоже есть API! Этим мы и воспользуемся)
API ( application programming interface ) — программный интерфейс приложения.
В частном случае, он позволяет работать с приложением из другого приложения (например, вашего скрипта) без привычного графического пользовательского интерфейса (GUI).
Если по-простому, то вы можете написать программу, которая будет работать с сервисом вместо вас!
Мы будем использовать API Директа, чтобы спарсить выдачу Wordstat по заданному списку ключевых фраз, минус-слов и региону сбора. Т.е. будем делать автоматически то, что в прошлый раз делали с помощью плагина Wordstat.Assistant, НО с возможностью автоматизации и больших объемов сбора (десятки тысяч фраз за раз)!
Сбор ключей нужен не только для настройки рекламных кампаний, но используется для SEO-продвижения сайтов и даже групп ВКонтакте (об этом здесь).
План работы
- Создаем новое приложение в Директе;
- Получаем отладочный токен для доступа к приложению;
- Отправляем заявку на доступ (тестовый или полный, для задачи парсинга значения не имеет);
- Активируем песочницу;
- Устанавливаем интерпретатор языка Python (Питон) на свой ПК (если не установлен);
- Скачиваем с Github проект Yandex.Wordstat-parser и вместе разбираемся с примером;
- Адаптируете скрипт под свои нужды и наслаждаетесь автоматизацией!
Может, звучит и сложно, но, на самом деле, пугаться здесь нечего. Сейчас все подробно по шагам разберем. Было бы желание, а от результата точно кайфанёте)
Парсер кроссплатформенный. Это значит, что она работает как на ПК под Windows, так и на Linux и Mac
Создаем приложение в Директе
Первое, что нужно — это создать учетку в Яндексе, если, вдруг, у вас ее еще нет. Далее, переходим на страницу API Директа:
Ниже, в разделе «С чего начать» есть ссылка на подробный мануал по регистрации нового приложения. В конечно счете, нужно попасть на страницу создания нового приложения https://oauth.yandex.ru/client/new:
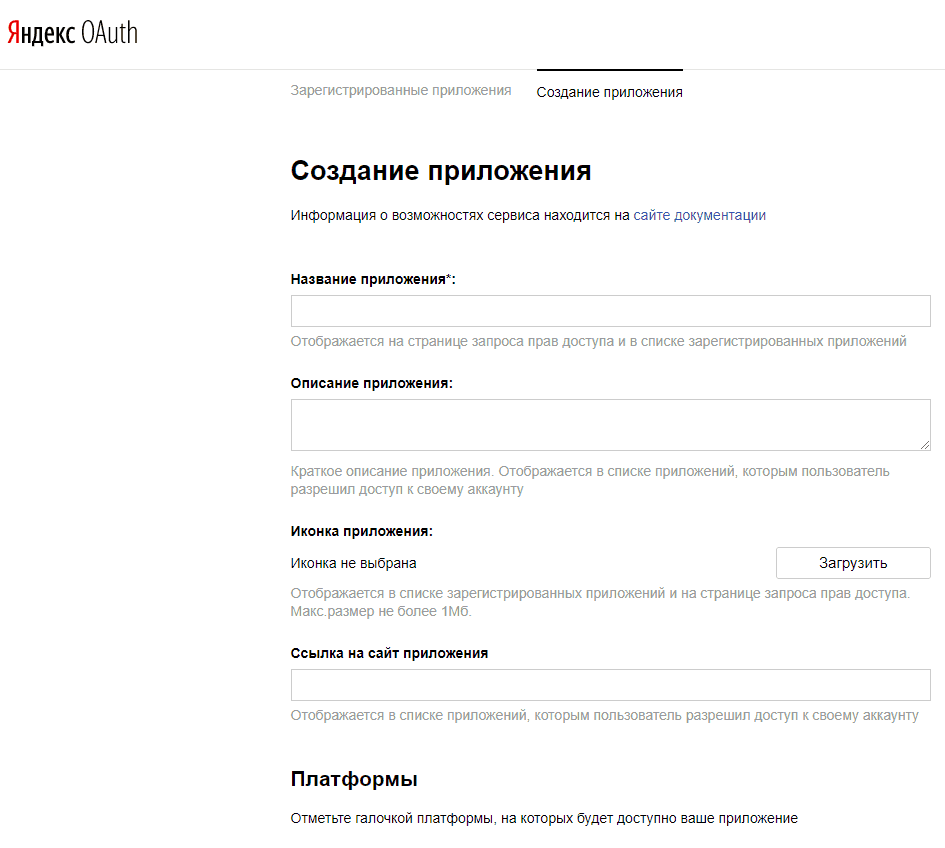
Заполняем необходимые поля:
- Название приложения: можете задать любое название (например, «парсер Яндекс Wordstat» или wordstat_parser»)
- Платформы: отмечаем «Веб-сервисы», подставляем Callback URL, путем нажатия кнопки «Подставить URL для разработки«. Это нужно сделать, чтобы мы могли получить веб-доступ к нашему будущему приложению
- Доступы: выбираем Яндекс.Директ -> Использовать API Яндекс.Директа
Остальное заполнять необязательно. Нажимаем «Создать приложение»:
Попадаем на такую страницу и копируем ID нашего приложения:
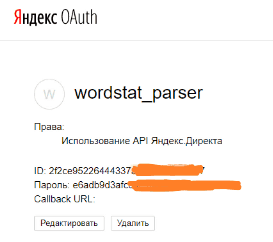
ID приложения понадобится при получении отладочного токена, который вы будете передавать из скрипта в приложение при каждом подключении. Этот механизм защищает ваше веб-приложение от несанкционированных подключений. Так, как речь идет об API Директа, т.е. о доступе к рекламному кабинету, где может быть ненулевой баланс, необходимость авторизации обоснована.
Получаем отладочный токен
Мы скопировали ID нашего приложения. Теперь, в адресной строке браузера пишем следующий URL с параметрами:
https://oauth.yandex.ru/authorize?response_type=token&client_id=<идентификатор приложения>
Вместо <идентификатор приложения> подставляем скопированный ID приложения (без скобок) и переходим по получившейся ссылке. Откроется окно, где указан ваш токен — ключ API Yandex:
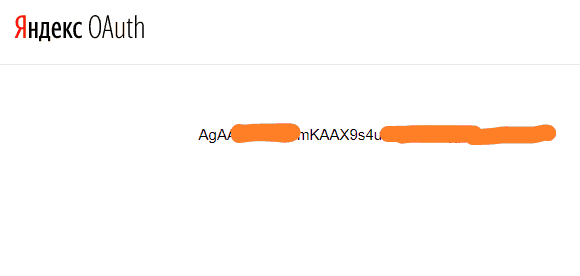
Поздравляю! Токен получен. Сохраните этот ключ в надежном месте, его мы будем вставлять в наш парсер Яндекс Wordstat.
Более подробно процесс получения ключа доступа описан в официальной документации.
Отправляем заявку на доступ к приложению
Наберитесь терпения, осталось немного) Чтобы Яндекс разрешил нам работать с приложением, нужно запросить доступ. Есть 2 варианта доступа: тестовый и полный. Для задач парсинга подойдет тестовый доступ, поэтому, именно его мы будем получать.
Переходим на страницу управления заявками: https://direct.yandex.ru/registered/main.pl?cmd=apiCertificationRequestList

У меня уже есть одобренная заявка (при первом входе, потребуется принять пользовательское соглашение, после чего, получите страницу подобного вида). Вам же нужно нажать кнопку «Новая заявка» -> «Тестовый доступ«:
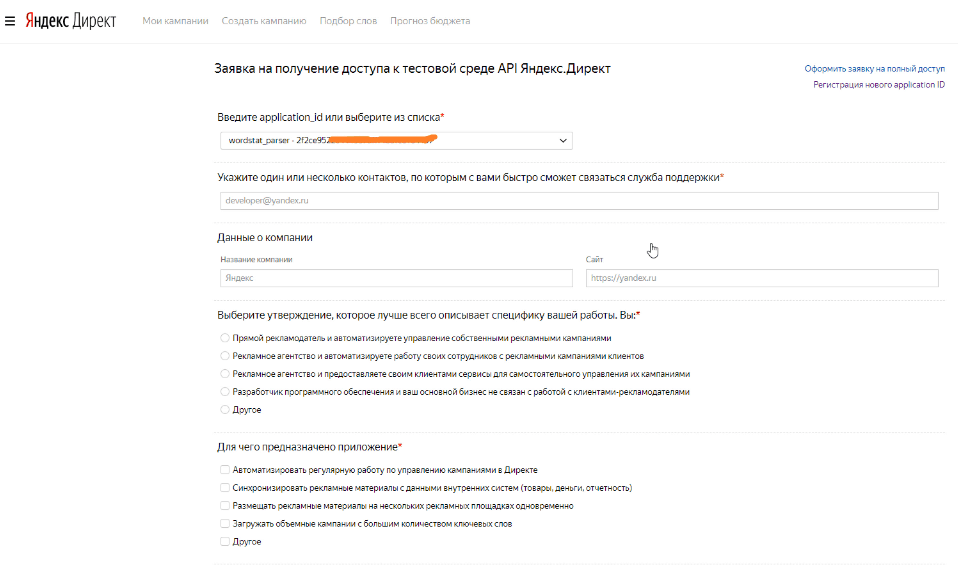
Заполняем необходимые поля:
- application_id: выбираете свое приложение из списка
- E-mail: ваша почта для связи
- Данные о компании: можно не заполнять
- Выберите утверждение…: здесь выбираем первый пункт «Прямой рекламодатель и автоматизируете управление собственными рекламными кампаниями»
- Для чего предназначено приложение: выбираем «Другое» и пишем честно, как есть. Например, «парсер Яндекс Wordstat«
- Основные функции приложения: выбираем «подбор ключевых слов (использование wordstat)«
- Какие новые возможности работы с Директом дает ваше приложение пользователям: пишем что-то в духе «автоматически подбирает ключевые фразы по заданным критериям«
- Ожидаемая дата завершения разработки: я писал примерно + месяц от сегодняшней даты. Влияет ли это на одобрение заявки, честно, не знаю
Читаем пользовательское соглашение. Если все устраивает, соглашаемся и отправляем заявку. Готово)
Имейте в виду, что на рассмотрение заявки может уйти несколько дней. Пока Яндекс не одобрит заявку, работать с парсером не получится.
Активируем песочницу
Не дожидаясь одобрения заявки, можно завершить последние приготовления, а именно, активировать песочницу. Для этого, перейдите в соответствующий раздел и нажмите кнопку «Начать пользоваться песочницей»:

Песочница — это пространство для тестирования. Вы можете работать с API Директа и, при этом, не сломать свою действующую рекламную кампанию.
Выбираем роль = «Клиент«, ставим галочку «Создать тестовые кампании» и жмем «Продолжить«. Песочница создана:
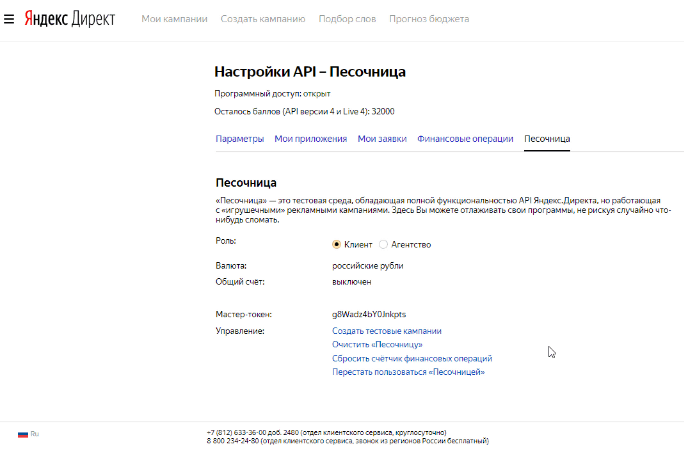
Проверяем, что ничего не забыли
Проверим, что мы должны иметь на данный момент:

- У нас создано приложение в Яндекс Директ
- Мы получили и сохранили отладочный токен (он же — Yandex API Key)
- Получено одобрение на тестовый доступ к нашему приложению
- Активирована песочница
Помним, что на одобрение заявки может уйти несколько дней. Чтобы не терять их впустую, предлагаю заняться подготовкой клиентской стороны (т.е. нашего ПК) к работе с парсером.
Устанавливаем Python
Первое, что нужно сделать — это установить интерпретатор языка Рython (он же — питон). Для этого, заходим на официальный сайт проекта и скачиваем подходящую для нашей системы сборку: https://www.python.org/downloads/

Почему именно Python? Я сделал выбор в пользу питона по двум причинам:
1. Очень низкий порог вхождения: даже непрограммист вполне в состоянии быстро разобраться с основами;
2. В официальной документации на API Директа примеры написаны, в том числе, на питоне

В целом, хотелось бы чуть больше рассказать о том, почему Python так хорош, но в одну статью это не влезет)
Я люблю Python за универсальность. Можно и чат-бота написать и сайты спарсить и рабочую рутину по сведению таблиц Excel автоматизировать. И это не говоря уже о фреймворке Django для веб-приложений на Python!
Приятный бонус — достаточно легко найти высокооплачиваемую работу (если вас это, конечно, интересует). Если задумаете изучить язык на серьезном уровне, рекомендую этот курс. Да, это не быстро (12 месяцев). Да, не бесплатно. Зато, результат обучения с лихвой окупит все вложения.
Дальше все стандартно: запускаем инсталлятор и следуем инструкциям.
Очень удобно, что из коробки вместе с интерпретатором поставляется простенькая среда разработки — IDLE. Конечно, разработчики с опытом уже имеют свою рабочую среду и, понятно, будут работать в ней, но для старта и первого знакомства, IDLE вполне достаточно.

Лично я, в своей работе использую среду Visual Studio Code. Мои скромные потребности она полностью удовлетворяет: интеграция с Git, подсветка и дополнение кода, линтер, встроенный терминал и удобный отладчик. К тому же, она бесплатная) Если захотите чуть глубже окунуться в разработку — рекомендую.
Поздравляю, с подготовкой мы закончили)
Работаем с Yandex.Wordstat-parser
Я написал небольшой класс для работ с API Яндекс Директ в части парсинга ключей из Вордстат. Делал я его для себя и своими силами, поэтому, на идеальный вариант он никак не претендует, но, со своими задачами справляется неплохо) Обсуждение в комментариях приветствуется.
Есть 2 способа установить его: просто скачать с GitHub или с помошью Git (продвинутый способ). Рассмотрим оба варианта.
Качаем парсер Яндекс Wordstat с GitHub
Это очень просто:
- Переходим в репозиторий на GitHub по ссылке: https://github.com/igor-kantor/Yandex.Wordstat-parser

- Нажимаем зеленую кнопку «Clone or download» — > «Download ZIP»;
- Распаковываем архив в любую удобную директорию;
- Готово! Парсер яндекс wordstat уже у вас)
Установка с помощью Git
Тоже самое можно сделать одной простой командой в командной строке, конечно, при условии, что у вас установлен клиент Git:
git clone https://github.com/igor-kantor/Yandex.Wordstat-parserGit — это одна из самых распространенных систем контроля версий программного обеспечения. Многие разработчики используют ее для управления своим кодом и совместной работы над программным продуктом.
GitHub — популярный провайдер Git, предоставляющий место хранения и коллективной работы над исходными кодами.
Установить клиент Git можно отсюда. После установки, команды git станут доступны из командной строки. В некоторых случаях, требуется дополнительно прописать путь к git в переменную реды PATH. Если будет интерес к теме работы с Git — пишите в комментах, может, подготовлю небольшую статью.
Настраиваем скрипт и начинаем парсить!
У нас есть папка с файлами, скаченными с GitHub:
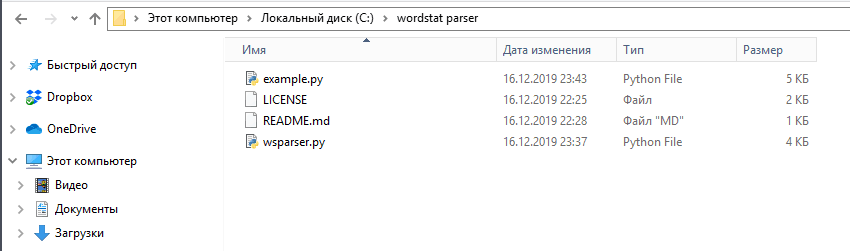
Класс для работы с API Директа содержится в файле «wsparser.py«. Его трогать не нужно.
В файле «example.py» приведен пример работы с классом wsparser — это и есть парсер Вордстата, в который нужно подставить наши исходные данные.
Открываем файл «example.py» в IDLE (или в любом текстовом редакторе) и вводим свой ключ api yandex, он же — отладочный токен (как его получить, читай выше) — параметр token, и ваш логин в Яндекс — userName:

Параметр url можете оставить без изменения. Если вы получали полный доступ и хотите работать с API Директа не в режиме песочницы, то укажите вместо этого, адрес, указанный строчкой выше (адрес полного доступа). Для парсинга в этом нет необходимости.
Далее, указывается список минус-слов (подробнее, в этой статье), свой список фраз и география (если требуется), по которым хотите собрать выдачу. :

Если хотите уточнить географию — это делается указанием кода региона и/или города в параметре geo.
Больше никаких настроек делать не нужно) Сохраняете файл и запускаете на исполнение. Файл содержит подробные комментарии ко всем действиям — настоятельно рекомендую ознакомиться!
Запуск скрипта
Для запуска скрипта на исполнение достаточно в верхней части окна нажать Run — > Run Module. Откроется терминал Python Shell, куда будет выводиться лог выполнения скрипта. Если все сделали правильно, то увидите нечто подобное:

Теперь откройте папку, где лежит «example.py«:

В файлах «phrases_left.txt» и «shows_left.txt» лежат фразы и частотность левой колонки выдачи Wordstat. В файлах «phrases_right.txt» и «shows_ right .txt» — правая колонка (похожие запросы). За один проход собирается 300 фраз левой колонки для одной фразы. У нас было 2 фразы на входе («фотошоп» и «photoshop»), поэтому, в результате, мы получили 600 фраз на выходе.
Ограничения API Директ на парсинг
Баллы API Директа
Если вы обратили внимание, то в логе парсера первой строчкой приводится информация о том, сколько баллов у нас осталось. При первом запросе результат будет 32000. При втором, уже 31980.
Баллы API — это, своего рода, валюта API Директа. Запрос выдачи по одной фразе стоит 10 баллов. Когда баллы закончатся, запросы обрабатываться перестанут.
Так у Яндекса реализован механизм ограничения нагрузки на сервера обработки.
Хорошая новость! Баллы со временем автоматически пополняются.
У нас за 1 запрос парсилось 2 фразы, поэтому, сняли 20 баллов.
Отчеты
Другие ограничения связаны с тем, что результаты парсинга возвращаются в виде отчетов. Кол-во отчетов на одного пользователя ограничено 5 штуками. При попытке сформировать шестой отчет будет получена ошибка. Поэтому, если вы заметили, в скрипте, кроме методов создания и получения отчета createReport, getReportList и readReport используется метод для удаления отчетов с сервера — deleteReport.
Еще ограничение: в одном отчете можно получить результаты сбора только для 10 фраз.
Для более глубокого парсинга вы можете модифицировать алгоритм скрипта под себя и сделать двух- и даже трехпроходовый парсер Яндекс wordstat. Для этого, после получения первых 300 ключевых фраз (если парсили одну фразу) можно разбить результат на 30 групп по 10 фраз и снова запрашивать отчеты, уже по 10 фраз. Потребуется запросить 30 отчетов.
Заключение
Конечно, есть достаточно много хороших и не очень инструментов, упрощающих жизнь SEO-шников, директологов, арбитражников и вебмастеров.
Для себя я уже сделал выбор в пользу десктопного софта — KeyCollector (не путать с названием моего блога?). Это мощный инструмент, облегчающий работу по сбору и анализу больших ядер в сотни тысяч ключей. Цена инструмента вполне демократичная, а функционал покроет почти любые потребности.
Тем, кто хочет получить результат еще быстрее и без установки дополнительного софта — попробуйте замечательный инструмент для парсинга Wordstat от команды Rush Analytics. Есть бесплатный период, очень удобный интерфейс и, самое главное, он работает в облаке! Это не только удобно, но и гораздо быстрее десктопных приложений.
Тем не менее, надеюсь, что моя статья сподвигнет кого-то на изучение чего-то нового для себя. Разве не от новых достижений мы получаем свою порцию дофамина?) Возможно, кому-то окажется полезным класс на Python и вы используете его в реальном проекте или для создания собственного софта.
С вами был Игорь Кантор, не забывайте подписываться на новости! Всем профита!









Доброго времени суток, Игорь!
Попытался по вашему кейсу сделать парсер но вышла заминка в доступе к приложению API Директа. Мне 3й раз сейчас отказали с комментарием:
«Заявка отклонена. Инструмент для получения статистики поисковых запросов (метод CreateNewWordstatReport и смежные) являются неотъемлемой частью API Директа и самого сервиса Яндекс.Директ. Сам же сервис предназначен исключительно для активных пользователей — в частности рекламодателей. Использование API Директа только для получения данных о статистике поисковых запросов не является целевым использованием сервиса, так как не ведет какого-либо взаимодействия с основными объектами, например рекламными материалами.»
Сталкивались ли с такой проблемой и может знаете как решить ее?
Евгений, здравствуйте!
Я не сталкивался, но предполагаю, что Яндексу не понравилась заявка, а именно, ответ на вопрос «Для чего предназначено приложение». Попробуйте указать что-то в духе «автоматизация управления бюджетом РК». Для чистоты, можно в коде какой-нибудь метод соответствующий упомянуть.
Написал им в поддержку и получил такой ответ:
Добрый день, Евгений!
К сожалению, в данном случае мы не можем одобрить вашу заявку. Методы «CreateNewWordstatReport» и смежные являются неотъемлемой частью API Директа и самого Яндекс.Директа. Нецелевое использование этого сервиса может привести к каким-либо ограничениям в работе с ним. Если вы не планируете использовать Яндекс.Директ по прямому назначению, то это может считаться нецелевым использованием сервиса. Если вам нужны только данные сервиса Wordstat, то мы рекомендуем использовать общедоступный веб-интерфейс этого сервиса (https://wordstat.yandex.ru ) в ручном режиме.
Однако, в случае если вы все же планируете использовать Яндекс.Директ, то опишите, пожалуйста, более подробно, как и какие методы API Директа использует ваша программа: названия методов (включая наименование сервиса для API Директа версии 5); для каких целей используются методы; схема и последовательность вызова методов; с какой частотой производится вызов каждого метода (раз в минуту, раз в час и т.д.) и для каких целей выбрана именно эта частота. Также опишите, как программа производит обработку ошибок, возникающих при работе с API, и как программа учитывает текущие ограничения API Директа.
Решил попробовать воспользоваться их Директ.коммандером, вроде тоже самое получается но все равно не то, что мне надо)
не знаете какой-нибудь способ чтоб вордстат выдавал с определенного кол-ва запросов? например чтоб запросы у которых выше 10к не выдавались мне?
Можно спарсить в сервисе Rush Analytics, выгрузить в Excel и отфильтровать по собственным критериям.
В целом, спасибо за ценный комментарий — думаю, читателям будет полезно знать про дополнительные требования к описанию со стороны Яндекс.
Подскажите, что именно в URL указать? то что в примере?
Добрый день! Этот нужно указывать, если не в песочнице: url =’https://api.direct.yandex.ru/v4/json/’
а если в песочнице?
Тогда, как в примере: url =’https://api-sandbox.direct.yandex.ru/v4/json/’
сорри, затупил что-то)
ну пока пишет: >>> Поймано исключение: (‘Не удалось получить баллы’, {‘error_code’: 58, ‘error_str’: ‘No access’, ‘error_detail’: ‘You need to fill out an app access request in the Direct interface and wait for confirmation’}) видимо из-за того что заявка модерацию не прошла.
Вероятно. Мне уже подписчики блога писали, что модерация режет, когда в качестве приложения парсер заявляли.
при получении отладочного токена выходит ошибко 400 Отсутствует необходимый параметр redirect_uri , ссылка со своим идентификатором приложения.. в чем причина?
уже решилось